Let's put the Router class to good use.
First, we define the routes that our application needs, and then we use the build_response method on the router to generate the HTTP response.
Let's update the app.rb script as follows:
# weby/app.rb
require_relative './router'
class App
attr_reader :router
def initialize
@router = Router.new
router.get('/') { "Akshay's Blog" }
router.get('/articles') { 'All Articles' }
router.get('/articles/1') { "First Article" }
end
def call(env)
headers = { 'Content-Type' => 'text/html' }
response_html = router.build_response(env['REQUEST_PATH'])
[200, headers, [response_html]]
end
end
Note that we're setting up the router and initializing the routes in the constructor, and not in the call method. This is important. The constructor is called at the beginning when the application starts, and never again. In contrast, the call method is invoked every time a new request comes in. We want to initialize the router only once, at the beginning.
And we're done. Restart the application, and be prepared to be amazed.
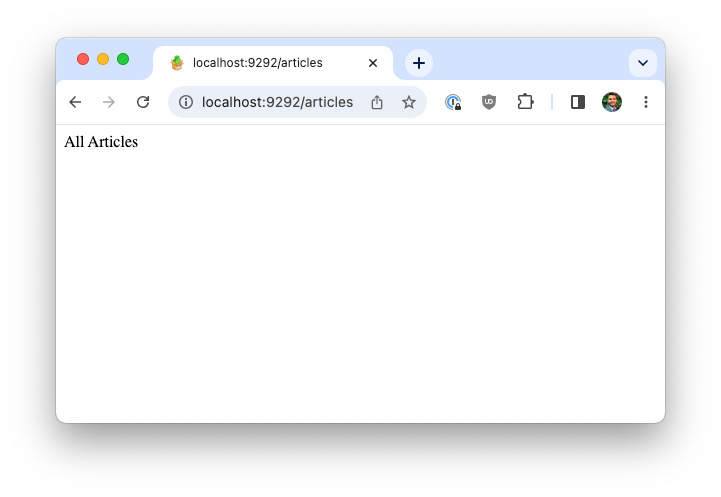
Other routes work as expected, too.
$ curl localhost:9292
Akshay's Blog
$ curl localhost:9292/articles
All Articles
$ curl localhost:9292/articles/1
First Article
$ curl localhost:9292/articles/x
no route found for /articles/x
$ curl localhost:9292/random-url
no route found for /random-url
We have a functioning router implementation. Woohoo!
But It Doesn't Look Like Rails!
At the start of the post, I promised the following router API that looked similar to what we have in Rails.
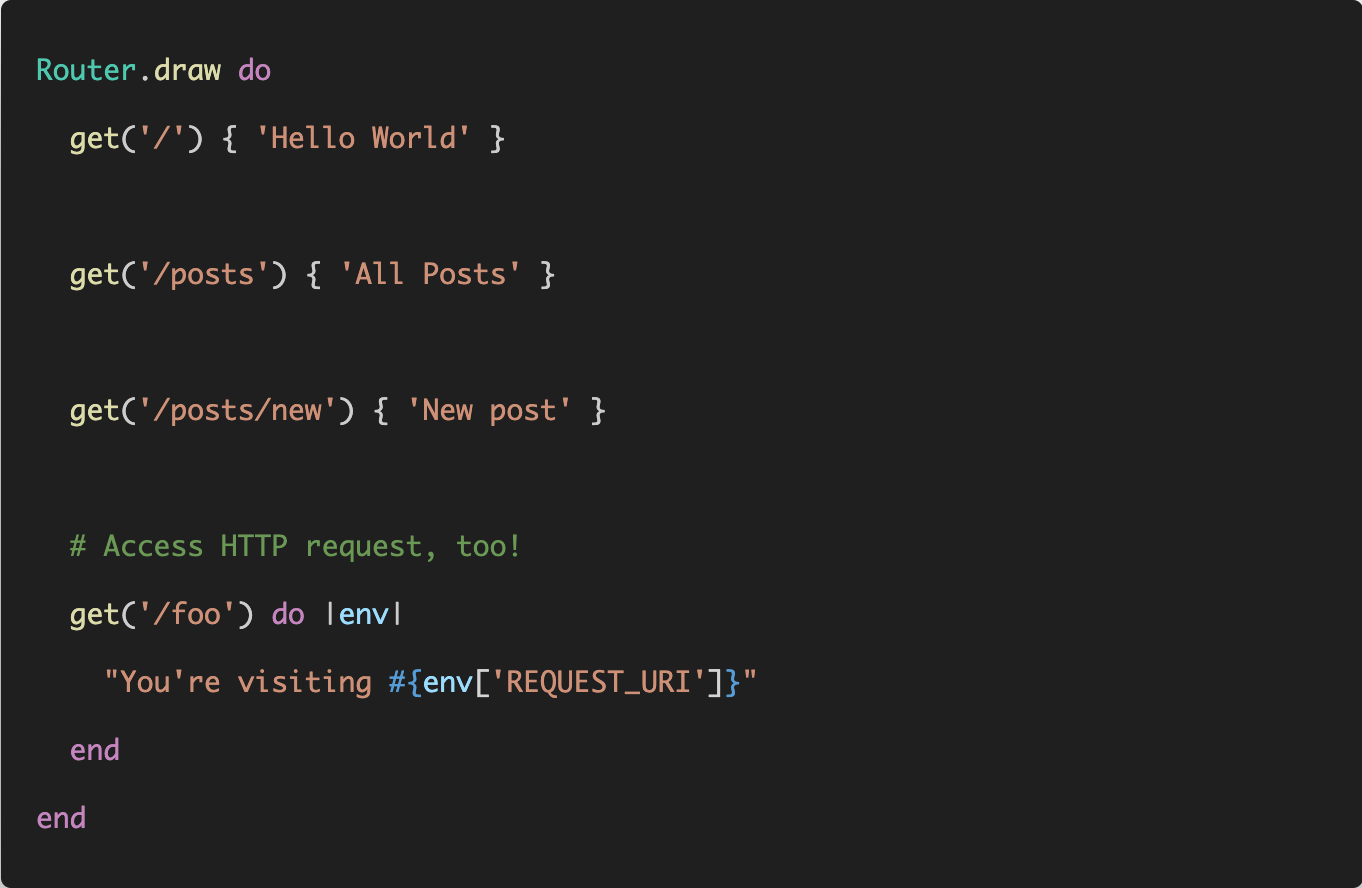
The current implementation doesn't look like that at all!
I know, I know. I decided to build the simplest router first as jumping directly in the above implementation would've meant compressing a lot of things together. But now that we have a simple and functioning router, we can refactor and improve it to make it more Rails-like in three simple steps:
Refactor the Router
Create the Routes
Update the application to use new routes